
Many files are stored in the memory of the computer system, when these files are required by the application then the operating system has to read the computer memory and access the required files.
There are several ways the operating system can access the information in the files. These methods are also known as file access methods. The two major file access methods that operating system support –
- Direct Access
- Sequential Access
- Index Access
Each file access method has its advantages and disadvantages which you will find in this article in greater detail.
Sequential access
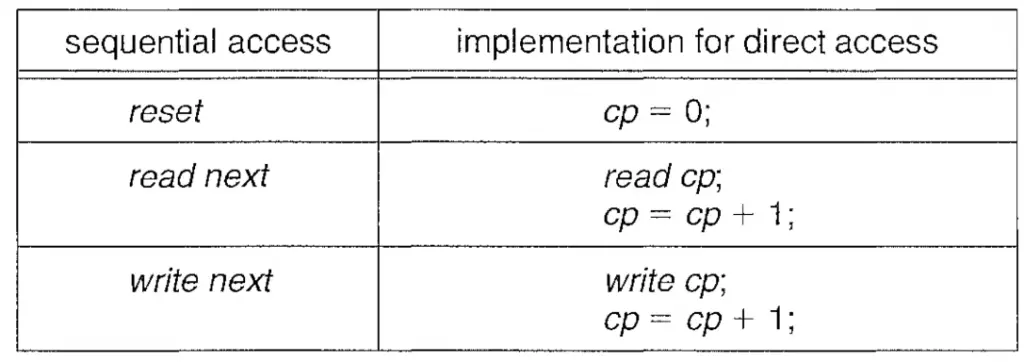
This method is one of the simplest and easiest ways to access the information in the files. The access of the information in the files occurs sequentially i.e. one record after the other. Due to the simplicity of this file access method, it is used by the compilers and editors.
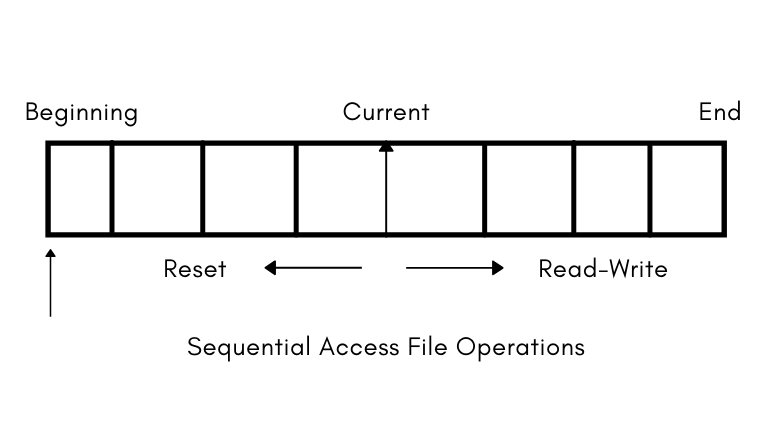
Sequential access file operation involves
Read next Write next Reset (or Rewind)
In this file access method, most of the operations are read and write operations –
The Read Operation – read next – reads the next portion of the file that is currently in access, also the read next advances the file pointer which is responsible for tracking the I/O operations.
The Write Operation – write next – write operation will add a new node at the end of the file and move the pointer to the new end of the file where the newly written information is stored.
Reset (or rewind) – reset operation will bring the file read or write head at the beginning of the file.
The sequential file access method depicts the example of how a tape drive worked, one memory block at a time and then the next block followed.
Advantage – The sequential access method is an easy implementation method for the software and hardware.
Disadvantage – The sequential access takes a lot of time for performing the read-write operation.
This is due to the reason that it accesses the information in the file one record after another, this is dealt with in the direct access method.
The file allocation methods in operating system which is mechanism to store the files in the memory uses both or either of direct access or sequential access method to access memory after being allocated.
Direct Access ( or Relative Access)
The direct access method represents the disk model of a file, as the disk allows random access to any file block, and so does the direct access. The file is divided into fixed-length blocks and the file is viewed as a numbered sequence of these blocks. Therefore the operating system can perform a read-write operation on any random numbered block when provided. For example, the operating system may read block 2, then block 7 and then write on block 13.
Also, the user always provides the relative block number to the operating system to access the particular block, whereas the absolute block number where the block is stored is only known to the operating system. For example, the first relative file block number is 0 and the next block number is 1 but the absolute block number in the memory may be 21033 and 30122. This also prevents the user from accessing the files that are not part of the required file.
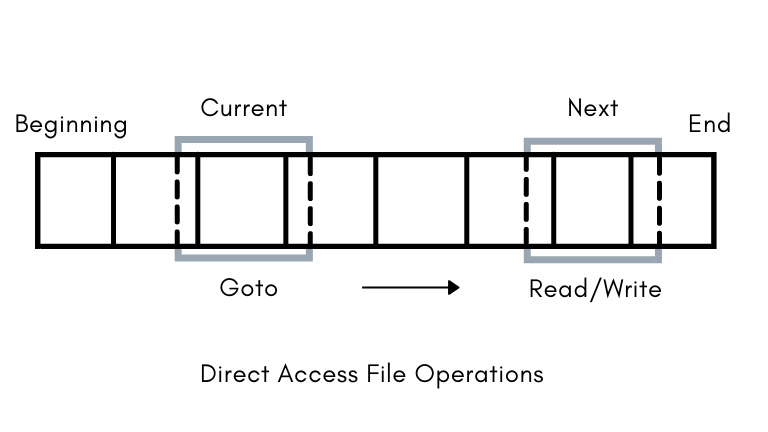
Direct access file operation involves
Read n Write n Goto n
The ‘n’ represents the block number.
Advantages – the direct access method solves the problem of sequential access and helps to access the information in the file immediately.
The best example of direct file access is the database system. When the database system receives queries, it calculates which block has the desired information and then returns the information to the user.
We can simulate the sequential access method with the direct access method but vice versa can be inefficient and complex.
Index Access
The Index Access method is an improvised version of the direct access method. In this method, an index is maintained which contains the address (or pointers) of the file blocks. So, to access any particular record of the file the operating system will first search its address in the index and the index will then point to the actual address of the particular block of the file that has the desired information.
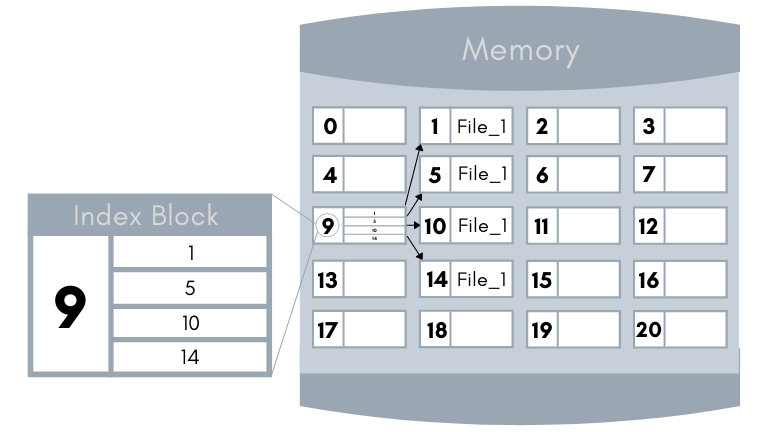
When the information is kept on adding to a particular file then the number of file blocks increases. This growth in the file blocks also grows the index of that file. At one point in time, the index of the file block may become too large to be kept in memory. The solution to this problem is to create an index for the index file. The primary index file contains the pointer (or address) to the secondary index file and the secondary index file contains the actual address of the blocks of the file. This method can be repeated as the file size continues to grow.
For example – To find the desired item, the operating system will perform a binary search on the primary index. This will provide the operating system a block number for the secondary index. The operating reaches the secondary index and again performs a binary search and the block number is found that contains the desired result. The final block is then searched for the result.
Aayush Kumar Gupta is the founder and creator of ExploringBits, a website dedicated to providing useful content for people passionate about Engineering and Technology. Aayush has completed his Bachelor of Technology (Computer Science & Engineering) from 2018-2022. From July 2022, Aayush has been working as a full-time Devops Engineer.