
Spooling is a computing term which stands for Simultaneous Peripheral Operations Online. One of the main uses of Spooling is to copy data from one device to another where in one of the devices is considerable faster than the other device.
How Spooling works in Operating System
Spooling basically involves creating a buffer called SPOOL, which is used to hold off jobs and data, till the device in which the SPOOL is created is ready to make use and execute that job or operate on the data.
When a faster device sends data to a slower device to perform some kind of operation then the slower device uses any secondary memory attached to it as a SPOOL buffer and then this data is kept in the SPOOL till the slower device is ready to perform the operation on this data. When the slower device is ready then the data in the SPOOL is loaded on to the main memory for the required operations.
You can understand this concept by looking at the image below.
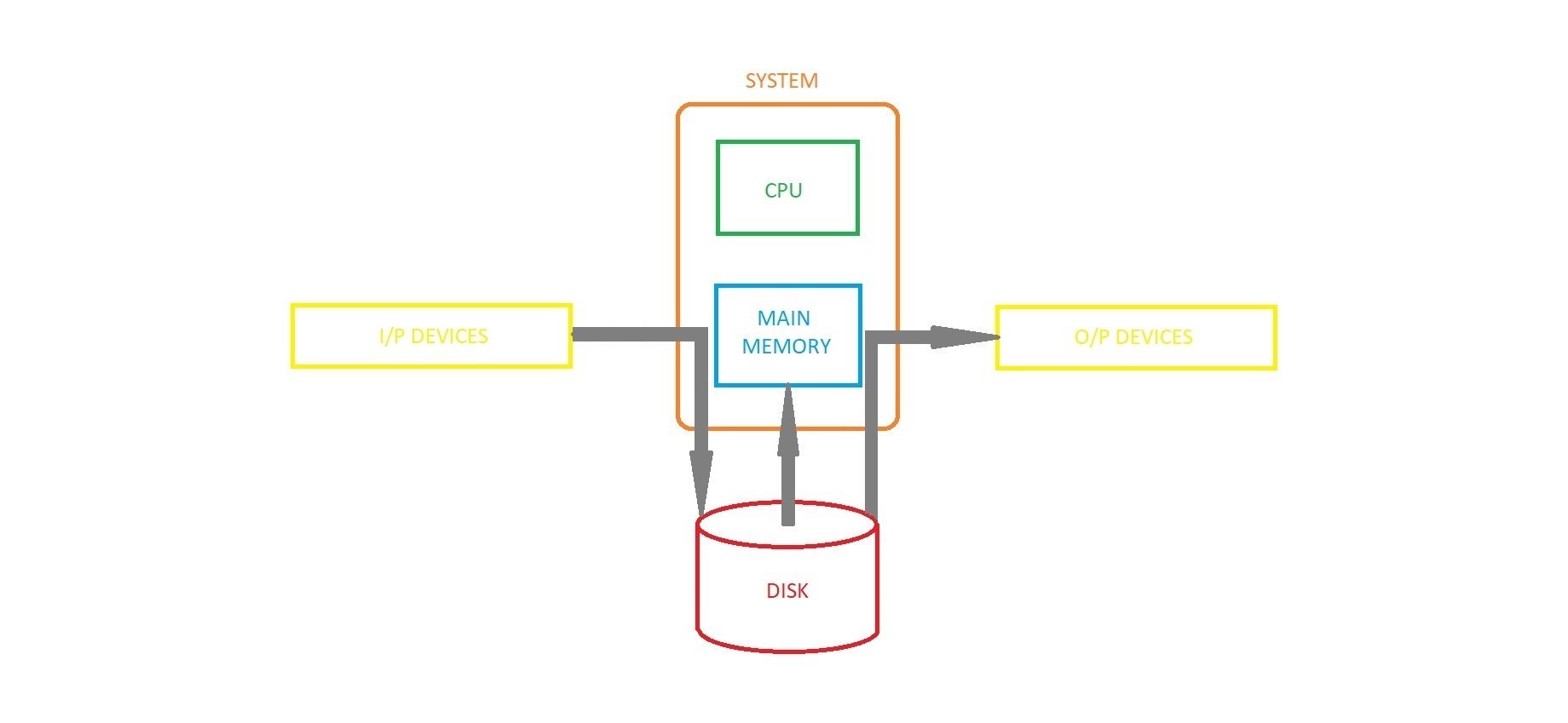
Spooling considers the entire secondary memory as a huge buffer which can store many jobs and data for many operations. The advantage of Spooling is that it can create a queue of jobs which can be executed in FIFO (First In – First Out) order to execute the jobs one by one.
A device can be connected to many input devices which may require some operation to be done on their data. So, all of these input devices may put their data onto the secondary memory (SPOOL) which can then be executed one by one by the device. This will make sure that the CPU is not idle any time. So, we can say that Spooling is a combination of buffering and queueing.
After the CPU generates some output, this output is first saved in the main memory. From the main memory, this output is transferred to the secondary memory and from there the output is sent to the respective output devices.
Example of Spooling
The biggest example of Spooling is printing. The documents which are to be printed are stored in the SPOOL and then added to the queue for printing. During this time, many processes can perform their own operations and use the CPU without having to wait while the printer executes the printing process on the documents one-by-one. Many features can also be added to the Spooling printing process like setting priorities or giving a notification to the user when the printing process has been completed or selecting the different types of paper to print on according to the user’s choice.
Advantages of Spooling in OS
- The number of I/O devices or operations do not matter. Many I/O devices can work together simultaneously without any interference or disruption to each other.
- In spooling, there is no interaction between the I/O devices and CPU. This implies that there no need for the CPU to wait for the I/O operations to take place. Such operations take a long time to finish executing so the CPU will not wait for them to finish.
- CPU in the idle state is not considered very efficient. Most protocols are created to utilize the CPU efficiently in the minimum amount of time. Spooling is also such a process. In spooling, the CPU is kept busy most of the time and only goes in the idle state when the queue is exhausted. So, all the tasks to be completed can be added to the queue and the CPU will finish all those tasks and then go in the idle state.
- It allows applications to run at the speed of the CPU while operating the I/O devices at their respective full speeds.
Disadvantages of Spooling in OS
- Spooling requires a large amount of storage depending on the number of requests made by the input and the number of input devices connected.
- Because the SPOOL is created in the secondary storage, having many input devices working at the same time may take up a lot of space on the secondary storage and thus increase disk traffic. This results in the disk getting slower and slower as the traffic increases more and more.
- Spooling is used for copying and executing data from a slower device to a faster device. The slower device creates a SPOOL to store the data to be operated upon in a queue, and the CPU works on it. This process in itself makes Spooling futile to make use of in real time environments where we need real time results from the CPU. This is because the input device is slower and thus produces its data at a slower pace while the CPU can operate faster so it moves on to next process in the queue. This is why the final result or output is produced at a later time instead of in real time.
Applications of Spooling in OS
- The most common application of SPOOLING can be found in peripheral I/O devices like keyboard, mouse and printers. In a printer, the documents or pages that are supposed to be printed are sent to the printer. The printer stores these documents/ pages in its main memory, termed as Printer Spooler. Once the printer is ready for printing, these documents are fetched from the Spooler and the printing process begins.
- As explained above, while the documents are waiting to be printed by a printer, other processes can work on their own documents and add them to the queue for printing. This is just a sophisticated example of the fact that SPOOLING is capable of overlapping the operations of different processes of multiple input or output devices with each other without any waiting which is a very efficient way of doing things.
- A Banner Page or a Burst Page is a page of a print job and it is used as a separator of different printing processes so that the system knows when a new printing process has begun. This page is added to the beginning and end of a printing process so as to mark the beginning and end of the job. The Banner pages also contain information to identify which port or process has requested the printing job. In this case, SPOOLING can also be used to generate these Banner Pages. This is useful in a place where a lot of people use the same printer.
- The concept of SPOOLING is also used in Electronic Mails (E-Mails). A software known as the Mail Transfer Agent or the Mail Relay is responsible for delivering a mail. This mail is temporarily stored in a temporary storage area. The mail then waits till it is picked by another software known as the Mail User Agent. This process is also known as the Store and Forward Mechanism.
- Batch Processing System is a system in which an OS collects the data which is to be processed and operated upon together in a group called a Batch and then starts processing them. This system uses the concept of SPOOLING to create and maintain a queue of the data and operations. The system can start working on the jobs in this queue one-by-one as soon as the required resources are available.
Aayush Kumar Gupta is the founder and creator of ExploringBits, a website dedicated to providing useful content for people passionate about Engineering and Technology. Aayush has completed his Bachelor of Technology (Computer Science & Engineering) from 2018-2022. From July 2022, Aayush has been working as a full-time Devops Engineer.